

Introduction
There are different configuration items and files available in the Prancer framework. The Prancer framework is at the heart of the Prancer Platform. The different configuration files available in the Prancer framework are as follows:
How does Prancer Framework operate in its most basic components?
Connector
The main configuration file is the connector, which is used to connect to different providers. It could be a cloud provider or a git provider. A connector encompasses enough information to connect to the supported external API providers. In the case of the git repository, it’s got the address of the git repository, the credentials, and the branch name. In the case of the cloud, it contains the required way to connect to the cloud, the iam user, secrets, and such information. The cloud could be any cloud supported by Prancer – Azure ,AWS or GCP.
Snapshot Configs
The Master Snapshot Config file contains the type of resource to get the configurations out of them , i.e. in the case of Azure, it could have the information to get all the virtual machines, all the vnets, or all the security groups. Master Snapshot configuration file cares about the types of resources from the cloud provider. In the case of the git, it could be to get all the JSON files, all the YAML files, all the terraform files, which again are types of resources being looked for. All the details to connect to various resource types are stored in the Master Snapshot Config file.
Inside the Prancer framework, there’s a crawling engine (a feature called crawler), which connects to the external provider using the connector, and based on the configuration that is present in the Master Snapshot Config file, it can find all the resources in the external provider, and generate another file called a Snapshot Config file.
In the Snapshot Config file, there are individual resources, unlike the Master Snapshot Config file, which contains the type of resources that we wish to get information about, e.g. when asking for virtual machines from the external provider, the crawler crawls the external provider resources and finds all the virtual machines present, for instance, vm-1, vm-2, vm-3, up until vm-10. In the case of git for Infrastructure as Code (IaC), the crawler connects to the git repository, based on the Master Snapshot Config file, which asks for all the YAML files, so the crawler finds all the individual YAML files in the git repository and generates a Snapshot Config file for the individual files that are available.
Tests and compliance tests
Another configuration file available in the Prancer frameworks is the Master Test file, which contains enough information to run tests against the type of resources that are present. For example, checking if all the virtual machines are using a public IP address, or testing all security groups and checking if they are using port 22 to allow an inbound SSH connection. All these test cases are stored in the Master Test file
On another side, we have the test file. A test file is related to individual resources. When the crawling feature is used, the test file is not being used, but when individual resources are used rather than the crawling feature, a test file is used for individual tests.
How all of these configuration files work together
Prancer framework uses the connector to connect to an external provider. The Crawler feature uses the Master snapshot configuration file to find all the resources mentioned in the master snapshopt configuration file and generate the snapshot configuration file which contains individual resources. Then the framework will generate Snapshots, which are the confirmation of the resources we want to keep for testing. Then the Compliance Engine can start running the testcases against the resources available as the snapshot, The tests and the compliance on these snapshots are run based on the master tests, and understood if those resources are compliant or not.
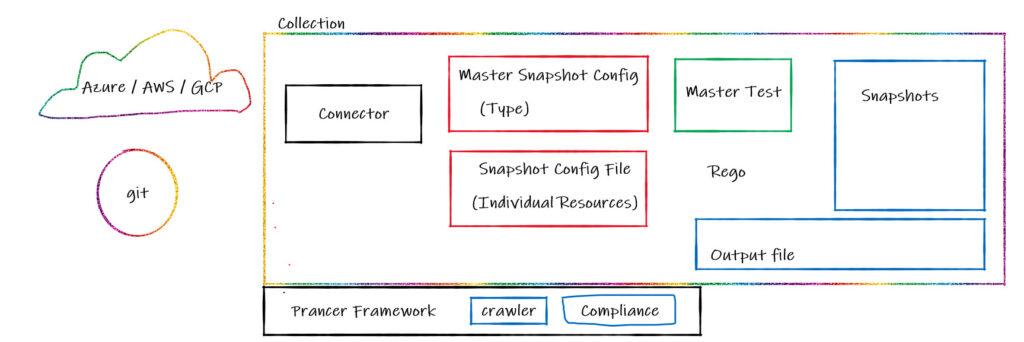
while running the testcases against the available snapshots, an output file is being generated which contains the report we are looking for. if the resource is passed or failed and the related compliance testcases. All the reporting details needed are available in the output file.
This process consisting of crawling and compliance tests can be run as many times as needed – based on the changes occurring in the cloud. All these configs and output files are stored in a container folder which is called Collection. We can have as many Collections as required for our testing purposes.
The Collection is a very powerful feature. We can use the Collection concept for various purposes. We can have a collection based on each project, based on each customer, or based on each business unit (based on how the user would like to interpret the collection in their specific business area).
A collection is basically like a folder that encompasses all these items. In the Prancer framework, there can be multiple collections, like a collection for Azure, one for AWS, one for the GitHub repository, one for a specific project in the git, and so on. Also, in each collection, there could be multiple connectors, multiple master snapshot config files, multiple master test files. It’s not restricted to a single file for each type seen here.
The concept of Collection gives the user a very powerful mechanism to scale up their security posture based on the Prancer framework.
Remote Configuration files
Prancer Framework supports two types of test formats. The simple testcases which are an inhouse query language on JSON files, and also tests based on the Open Policy Agent (OPA) Rego policy language, All the Rego test files are also available in the same collection, e.g. if there are 100 test cases based on the Rego, the files are available in the same collection directory. That’s how the people working with the Prancer framework do the compliance test.
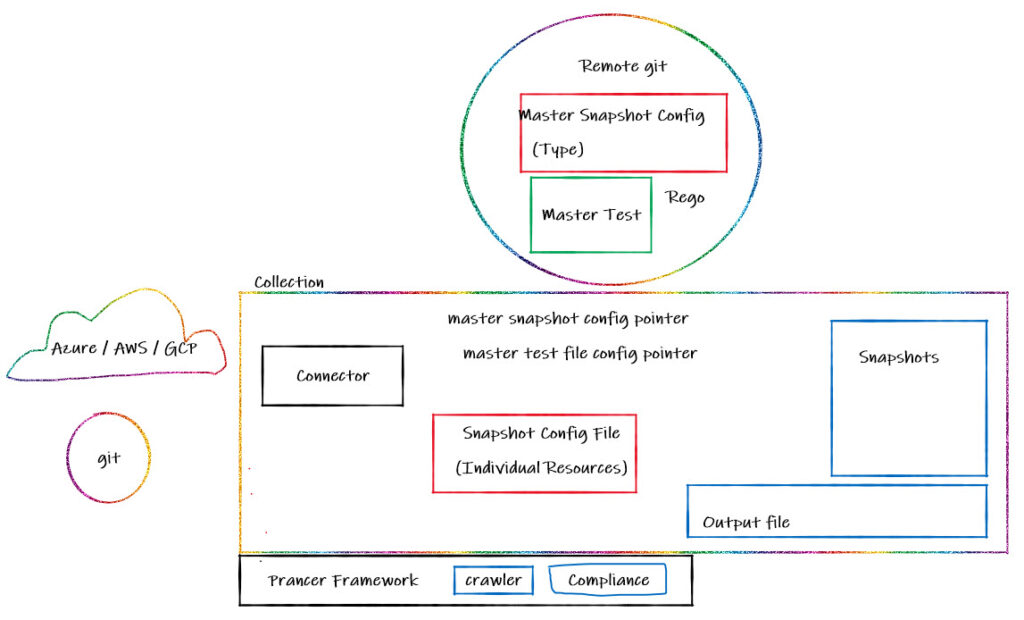
Suppose there are multiple Collections available for the company and the user wants to centralize the management of test files, Rego files, and snapshot files. It is possible to store all of these items in a remote git repository and read them from a centralized location. In this case, instead of creating the full Master test files and Master snapshot configuration files, 2 pointers are employed – a Master Snapshot Config pointer and a Master Test file config pointer – which point to the remote git which reads the information and gives the user the ability to leverage the power of Policy as Code and centrally manage the master test files, Rego files, and also the Master Snapshot Config files. The process for running the Prancer framework would be the same but instead of having a local Master Snapshot config, it connects to the remote git and gets the information from the remote master snapshot. And at the time of testing, the Compliance Engine connects to the remote master test files and the remote Rego files rather than the local files, but everything else like the snapshot and outputs will be stored locally in the collection.
In this article, I have introduced various configuration files available in the Prancer Framework, which is the heart of Prancer Platform. By understanding these concepts, you have an easier time navigating through our solution and understand the details of the application.

